Meta AI最近推出了一种“突破性”文本转语音 (TTS) 生成器,并声称其生成结果的速度比性能相当的最先进人工智能模型要快20倍。

Voicebox并不是传统意义上的TTS架构,而是采用更类似于OpenAI的ChatGPT以及Google Bard的模型。
Voicebox与类似的TTS模型(例如:ElevenLabs Prime Voice AI)之间的主要区别在于,它可以通过上下文进行学习。
与ChatGPT或其他模型非常相似,Voicebox使用大规模训练数据集。以前使用大量音频数据的努力导致音频输出严重退化。出于这个原因,大多数TTS系统都使用小型的、高度策划的、标记的数据集。
Meta通过一种新颖的训练方案克服了这一限制,该方案为能够“填充”音频信息的架构抛弃标签和管理。
正如Meta AI在6月16日的一篇博文中所说,Voicebox是“第一个可以泛化到语音生成任务的模型,它没有经过专门训练来完成最先进的性能。”
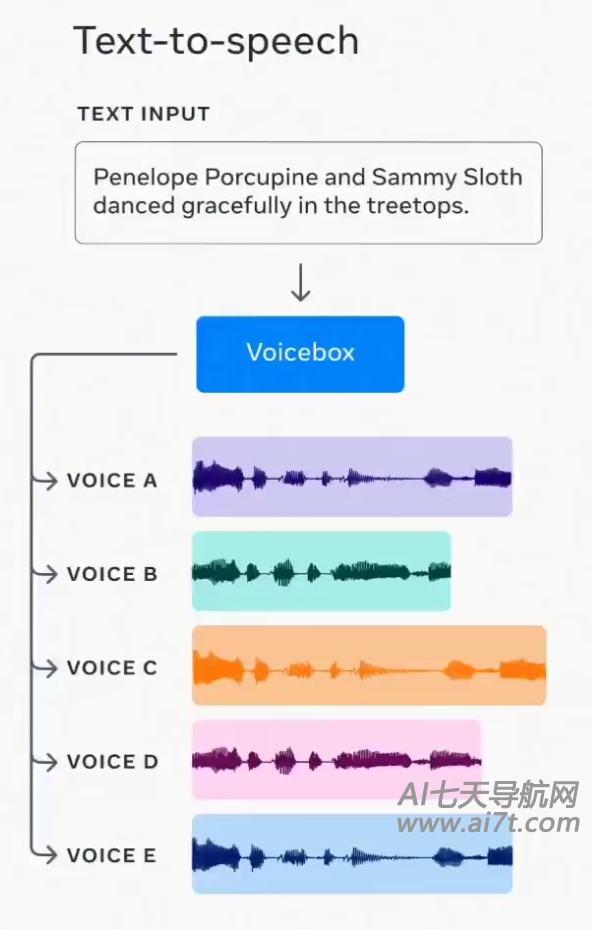
这使得Voicebox可以将文本翻译成语音,通过合成替换语音来消除不需要的噪音,甚至可以将说话者的声音应用于不同的语言输出。
根据Meta发表的研究论文,其预训练的Voicebox系统可以仅使用所需的输出文本和三秒钟的音频剪辑来完成所有这些工作。
Voicebox不是同类工具中的第一个,但它似乎是最强大的工具之一。 因此,Meta开发了一种工具来确定语音是否由它生成,该公司声称可以“简单地检测”真假音频之间的差异。 根据博客文章:
“与其他强大的新人工智能创新一样,我们认识到这项技术带来了滥用和意外伤害的可能性。在我们的论文中,我们详细介绍了我们如何构建一个高效的分类器,该分类器可以区分 Voicebox生成的真实语音和音频,以减轻这些未来可能存在的风险。”
Meta VoiceBox 视频下载
© 版权声明
文章版权归作者所有,未经允许请勿转载。

您好,这是一条评论。若需要审核、编辑或删除评论,请访问仪表盘的评论界面。评论者头像来自 Gravatar。